This article describes how keyboards interact with Unicode text, particularly cursor movement using arrow keys, text selection, and text deletion. It is intended to help specification authors and implementers understand how to document and build APIs related to these topics on the Web.
The Unicode Standard provides some implementation guidance, but this description is subject to interpretation. For example, Version 15.0, Section 5.11 (Editing and Selection) says, in part:
In some cases, editing a user-perceived “character” or visual cluster element by element
may be the preferred way. For example, a system might have the backspace key delete by using the
underlying code point, while the delete key could delete an entire cluster. Moreover, because of
the way keyboards and input method editors are implemented, there often may not be a one-to-one
relationship between what the user thinks of as a character and the key or key sequence used to input it.
There are four different (yet related) ways in which text selection and navigation interact with keyboards. In some cases, these different modes also apply to other selection mechanisms (such as using a pointing device such as a mouse or using a touch-based interface). This article describes these different modes, using examples from various languages and scripts that illustrate the corner cases.
Cursoring
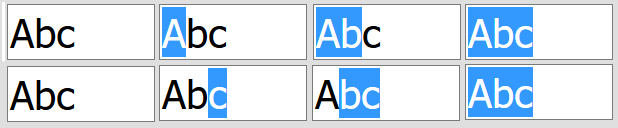
Cursor movement or "cursoring" is the process of moving through text using cursor keys on a physical keyboard. This is different from using a mouse or other pointing instrument (such as your finger in a touch interface), although a pointing device can often place the cursor (such as by "clicking" the cursor on the text or touching the text in an input field).
Text Selection
Text selection is the progressive process of selecting text in a document. Text selection on modern systems is done contiguously in memory, using the logical order of characters. When working with bidirectional text, this can produce multiple regions of highlighted text on the screen, although the characters are always adjacent in memory. (Some user interfaces also provide word-by-word or sentence-by-sentence selection, which we won't concern ourselves with here.)
Backspacing ("backwards deletion")
Backwards deletion deletes the text that is logically before the cursor. In horizontal text, these are the characters to the left of the cursor in left-to-right text such as in the Latin or Cyrillic script or to the right of the cursor in right-to-left runs of text, such as found in the Arabic or Hebrew scripts. Backwards deletion is most often associated with the "backspace" key on a keyboard. In this article we'll refer to backwards deletion as "backspace" or "backspacing".
Deleting ("forwards deletion")
Forwards deletion deletes text that is logically after the cursor (that is, in the opposite direction to the backspace key). Forwards deletion is often associated with the "delete" key present on some keyboards. (In this article we'll refer to this as "delete" or "deleting".)
Generally speaking, most text navigation and editing follows the user-perceived character boundaries. For most implementations this corresponds to Unicode's definition of "default extended grapheme cluster" boundaries [UAX29]. The main exception to this is backspacing, which usually follows Unicode code point boundaries in the underlying encoded text (although there are exceptions to this). For the simplest scripts and languages, these often amount to the same thing.
Cursor movement
Cursor movement, in the context of this document, refers to the use of the arrow keys on a physical keyboard (or their virtual equivalent).
One thing to note is that the arrow keys (left, right, up, and down) always refer to the same visual direction, regardless of the direction or writing mode of the text. On many systems, this behavior is different from what occurs when performing text selection using a pointing device.
Cursoring starts by positioning the cursor in the text, such as by clicking with the mouse. When cursoring in horizontal text, the left arrow button on a keyboard always moves the cursor one user-perceived character (grapheme) to the left, while the right arrow does the same in the opposite direction. The up and down arrows move the cursor up or down a row of text respectively.
In vertical text, the left arrow moves left one row and the right arrow right one row, while up and down arrows move one user-perceived character (grapheme) up or down in the row of text.
Selecting text via the keyboard
Text selection begins much like cursoring, by positioning the cursor at the start (or end) of the desired text and then selecting to the other end of the desired text. This can be done using a pointing instrument, such as a mouse, or using keyboard gestures such as holding "shift" and cursoring through the text. Unlike cursoring, text selection is constrained by the need to select logical characters, so a different number of keystrokes or gestures may be required compared to simple cursoring. This is particularly true for bidirectional text.
Selection using a pointing device, such as a mouse, is subtly different in most implementations than using the cursor keys to extend a selection. When using a pointing device, the selection is entirely logical, between the start and end point of the selection. At least on most physical keyboards, the user can access text selection, usually by holding down the "shift" key while cursoring in the text. As noted before, the cursor keys always move visually and in the indicated direction of the key. For certain bidirectional texts this can mean that the entire text cannot be selected via the cursor keys alone!
Combining characters
Selecting, cursoring, and deleting text in Unicode is also complicated by the use of combining characters. When the visual units of text map 1:1 to characters in the memory of the computer, then cursor movement, selection, and deletion traverse the text a character at a time. However, some languages and scripts use multiple characters to compose a single user-perceived character (which we call a grapheme cluster or grapheme for short). When this is the case, the relationship between cursor movement and delete or backspace functions becomes more complex.
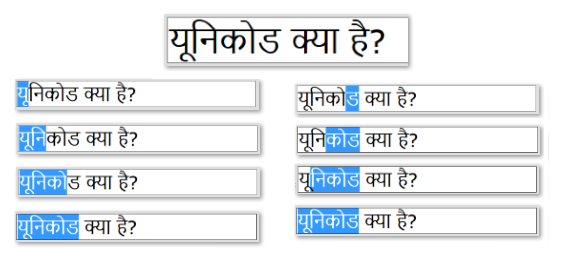
For example, the Hindi word for Unicode यूनिकोड is composed of seven Unicode characters from the Devanagari script.
Most users would identify this word as containing four units of text. Each of the first three graphemes consists of two characters: a syllable and a modifying vowel character (the last grapheme contains only a single character). So the word contains seven Unicode characters, but only four graphemes:
Word
यूनिकोड
Graphemes
यू
नि
को
ड
Code Points
य
ू
न
ि
क
ो
ड
U+092F
U+0942
U+0928
U+093F
U+0915
U+094B
U+0921
Cursor movement in this Hindi word matches the Unicode grapheme cluster boundaries in both the forward and reverse direction:
Usually cursor movement is expected to follow the boundaries of user-perceived characters, since users generally expect such movement to follow their perceptions. In addition, text selection captures complete graphemes, since a common operation is to copy a sequence of characters, possibly for later insertion elsewhere. Users don't expect to capture only a portion of a user-perceived character, nor do they want a cut operation to join any remaining combining marks with unrelated character sequences originally separated by some of the source text.
Forward deletion works the same way. If the user positions the cursor at the start of the Hindi word and presses the "delete" key four times, the entire word is removed, one grapheme at a time, like this:
Backspace, however, sometimes works differently. In this case, positioning the cursor after the same Hindi word and pressing backspace requires 7 key presses in order to erase the entire word as the characters are erased one Unicode code point at a time:
Try it in your browser
Try selecting, cursoring, deleting, and backspacing with this word in Hindi (in the Devanagari script). The word means "Unicode" and contains four graphemes and seven Unicode code points.
One reason suggested for the difference between delete and backspace behavior is that removing the base character (which is always the first character in a Unicode character sequence, and thus the first code point encountered in forward deletion) usually consumes any combining marks associated with it. That way combining marks associated with the base character aren't left over to combine with the preceeding sequence of characters, or, if there were no preceeding characters, be "orphaned" and form an invalid sequence.
Backspace, meanwhile, can safely remove combining characters hanging from a given base character without causing other characters in the character sequence to change meaning. One reason sometimes attributed for this behavior is that it allows characters that have been "built-up" using multiple keypresses or other input mechanisms to be corrected without retyping the whole sequence.
Tamil presents the same concept in a visually more striking way. The syllable கோ (pronounced like 'ko') looks as if it is made of three units. However, it consists of a two character sequence (U+0B95 U+0BCB), with the base character கU+0B95 TAMIL LETTER KA appearing visually in the middle. These characters still behave the same as those in the Hindi example: cursoring, selection, and forward deletion move over the pair as a single unit. Backspacing deletes the combining mark first.
Try it in your browser
South-Asian scripts, such as the Devanagari and Tamil examples above, are not the only ones affected by this; similar behavior can be found in any script that employs combining marks. For example, the first cluster in this Thai word ห้องน้ำ has similar behavior. The end of this word shows additional complexity: the ำU+0E33 THAI CHARACTER SARA AM appears as a separate typographical unit for effects such as inter-character spacing, but behaves as a single grapheme for the purposes of selection, cursoring, and forward deletion.
Try it in your browser
Some character sequences can be written in either a "composed" or a "decomposed" form that affect how backwards deletion performs. For example, Korean characters can be written in either a precomposed form or using a sequence of combining marks (called jamo). Here's one example:
Composed
Decoposed
각
각
ᄀ ᅡ ᆨ
U+AC01
U+1100 U+1161 U+11A8
When written in the precomposed form, each Korean character remains atomic for all operations. When composed from jamo, most systems allow backspacing into the character (while treating the character as atomic for selection and forward deletion).
Try it in your browser
This input field contains the precomposed character U+AC01:
This input field contains the equivalent Jamo sequence U+1100 U+1161 U+11A8
Korean is just an example of this. Ones that are less common in real life but are sometimes used as examples also help illustrate this mysterious "character duality". While most Latin script text with accents is encoded as precomposed characters, it is possible to encode most characters as a base character with one or more combining marks. When this decomposed sequence is used, the behavior is similar to the Korean: cursor, text selection, and forward deletion include the base character and all of its associated accents, while backspacing deletes the combining marks one-at-a-time before the base character is reached.
For example, the character U+01FA Latin Capital Letter A with Ring Above and Acute can also be composed as the sequence U+0041 U+030A U+0301. Both behave like a single letter for selection and deletion, but backspacing reveals the decomposed structure of the latter:
Try it in your browser
This field contains the pre-composed Latin character U+01FA
This field contains the decomposed (yet canonically equivalent) Latin character sequence U+0040 U+030A U+0301
For example, depending on your platform, emoji sequences sometimes behave as if they were atomic characters. For example, a "family" emoji such as 👨👩👧👧, when it is composed as an emoji sequence (here it is U+1F468 U+200D U+1F469 U+200D U+1F467 U+200D U+1F467), might be treated as a single unit of text for selection as well as both forwards and backwards deletion, while on other platforms the individual characters might be accessible to both the cursor and deletion.
Another counter case appears in some Indic script languages where some conjuncts are formed with multiple base characters. An example from the Devanagari script is the syllable kshi (क्षि) which is formed using the sequence U+0915 U+094D U+0937 U+093F. The characters U+0915 and U+0937 are both base characters and technically this forms two grapheme clusters. However, in many fonts (and to many users) this character sequence forms a single "shape" perceived to be a single unit of text. In spite of this perception, though, on some browsers the user can both cursor into the conjunct and forward delete only a part of the sequence.
Try it in your browser
This field contains one possible composed 'family' emoji, using the character sequence U+1F468 U+200D U+1F469 U+200D U+1F467 U+200D U+1F467
This field contains the Devanagari conjunct kshi
Vertical text
Vertical text works in a similar way to horizontal text with regard to text selection, cursoring, deletion, and backspacing. As you might suspect, cursor keys on a keyboard in general move the cursor in the direction of the arrow on the key. This usually means that, in vertical text, "up" is generally preceding the current cursor position logically, while "down" is generally following, while "left" and "right" navigate between lines of text.
Try it in your browser
Note: Not all browsers support vertical text modes yet, so this text might not be presented vertically in your browser.